Kmeans Clustering with wine dataset

#Step 1: Import required modules
from sklearn import datasets
import pandas as pd
from sklearn.cluster import KMeans
#Step 2: Load wine Data and understand it
rw = datasets.load_wine()
X = rw.data
X.shape
y= rw.target
y.shape
rw.target_names
# Note : refer more information from https://archive.ics.uci.edu/ml/datasets/Wine
# Step 3: Create model
model = KMeans(n_clusters=3)
labels = model.fit_predict(X)
labels
# Step 4: Understand actual Vs predications
df = pd.DataFrame({‘labels’: labels})
type(df)
def species_label(theta):
if theta==0:
return rw.target_names[0]
if theta==1:
return rw.target_names[1]
if theta==2:
return rw.target_names[2]
df[‘species’] = [species_label(theta) for theta in rw.target]
ct = pd.crosstab(df[‘labels’],df[‘species’])
ct

#Can we improve result by StandardScaler ?
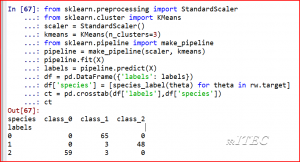
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
scaler = StandardScaler()
kmeans = KMeans(n_clusters=3)
from sklearn.pipeline import make_pipeline
pipeline = make_pipeline(scaler, kmeans)
pipeline.fit(X)
labels = pipeline.predict(X)
df = pd.DataFrame({‘labels’: labels})
df[‘species’] = [species_label(theta) for theta in rw.target]
ct = pd.crosstab(df[‘labels’],df[‘species’])
ct